
Fantasy Premier League is kind of a big deal here at The18. Friendships are strained over trash talk and sometimes it seems like people put more effort into perfecting each week’s lineup than their day-to-day duties.
When I joined The18 this year I had plenty of soccer knowledge but knew nothing about the arbitrary rules of Fantasy Premier League. But I had an idea: using the latest in data science and machine learning to derive the best possible fantasy team to conquer The18’s FPL league.
For those not in the know, Fantasy Premier League is a massive online competition where you essentially pick your best Premier League team (according to some constraints of course) and score points when your players do good things (score goals, assists, clean sheets, etc.) and get deducted points when your players do bad things (yellow/red cards, miss penalties, get a ton of goals scored on them, etc.). Therefore, the objective is to obtain as many points as possible on a weekly and season-long basis. Pretty simple right?
It's actually not. In addition to the abundance of rules set out that restrict your ability to pick the entire Liverpool or Man City squad, you have to make decisions such as who to captain (double points), who to put on the bench, and who to transfer and/or drop from your team. Lots of responsibility, I know.
Anyways, this will serve as the first installment in a blog-like series where I will chronicle my attempt to build a machine learning (or "artificial intelligence" if you want to really bring out the buzzwords) system that will dominate Fanstasy Premier League. I'm coming into this entirely new to FPL, so join me for the ride as I attempt to bring a data-driven perspective to the beautiful game.
On a brief side note, perhaps the hardest part of this whole process is coming up with a witty yet not try-hard team name that provides a small chuckle yet doesn't come across as researched. My original team name of "G-Money" understandably received a bit of blowback, so now I'm Grantchester United for the sole purpose of using my name as a pun.
Just a quick heads up — for those of you with a more technical background or who prefer to stare at hastily written Python code, the project is on Github as well.
Week 1 — Just Me and My Intuition
This was not the best of starts and perhaps even more motivation for building a system that can pick my team for me. I picked my first week's team with absolutely zero statistical reasoning and managed to captain Bruno Fernandes (who didn't have a game in Week 1), start Kyle Walker (also no game in Week 1) and drop a pretty penny on Firmino, who scored me a whopping one point. Time to whip out the math.
Week 2 — Doing Stuff With Numbers
Project Details and Data Exploration
A good way to kick off any data science project is locating viable sources of data — without this fun little step I should just call it quits now. In an effort to quickly produce a working minimum viable product, I'll start with this tremendous FPL repository, which contains historical and consistently updated data sets with all the FPL statistics you can imagine. However, moving forward, I won't restrict myself to just this data source but will also be considering any potential data that exists on the web that I believe may help in building this system.
Speaking of the system, the objective today is simply to build something that can predict total points scored for the next week.
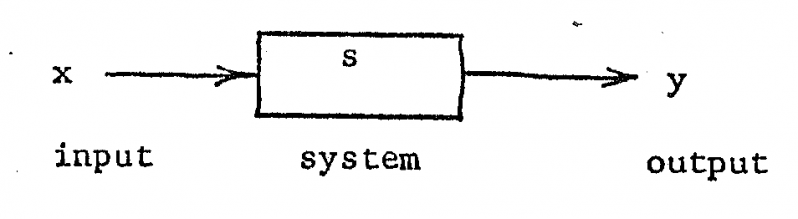
Pretty much anything can be structured into the above paradigm, but now that we have a clearly defined output (total points for next week), and a roughly defined input (data of some type), it's now time to engineer a system that can map the inputs to outputs.
So, the proposed system for this week is a linear model that predicts points for next week based solely on FPL data from the previous week. I'll track performance in relation to a baseline model, which, in layman's terms, is one with near-stupid reasoning that we use to compare our more sophisticated model to. Essentially, if our ML/AI model is not beating this simple baseline, why are we even going through all this trouble?
Also, a linear model just means that the variables I use as inputs will each be multiplied by some positive or negative number before all being added up. This sum will serve as the prediction for a player's total points in the following week (games are generally played on a weekly basis by the way).
Before we get into predictions, let's first take a look at the data and see what insights it holds. For clarity, data is provided for each player and includes notable variables such as:
- Player Name
- Bonus Points
- Clean Sheet
- Creativity Score
- Influence Score
- Threat Score
- Goals Conceded
- Goals Scored
- Assists
- Own Goals
- ICT Index Score
- Penalties Saved
- Penalties Missed
- Red Cards
- Number Selected by
- Total Points in the Week Before
- Transfers In
- Transfers Out
- Value
- Home/Away Game
We can visualize the relationships in the data with a correlation matrix. Values near 1 and -1 mean the two variables are positively and negatively correlated, respectively, while values around 0 indicate no correlation at all.
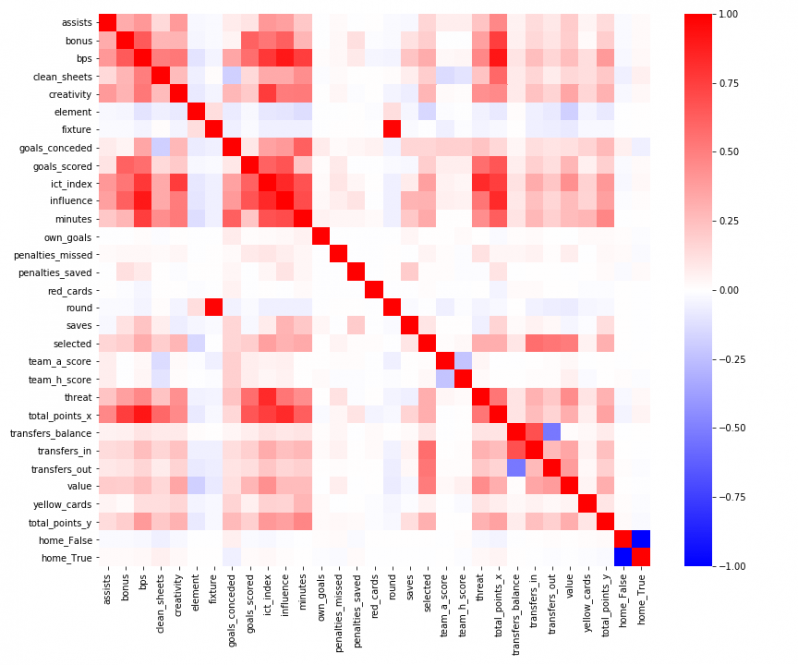
The above image is giving me a seizure — so for the sake of my health and in order to get a better feel for the variable we're predicting, let's look at scatter plots of the top four most-correlated variables to total points earned in the following week (the y-axis in all the plots).
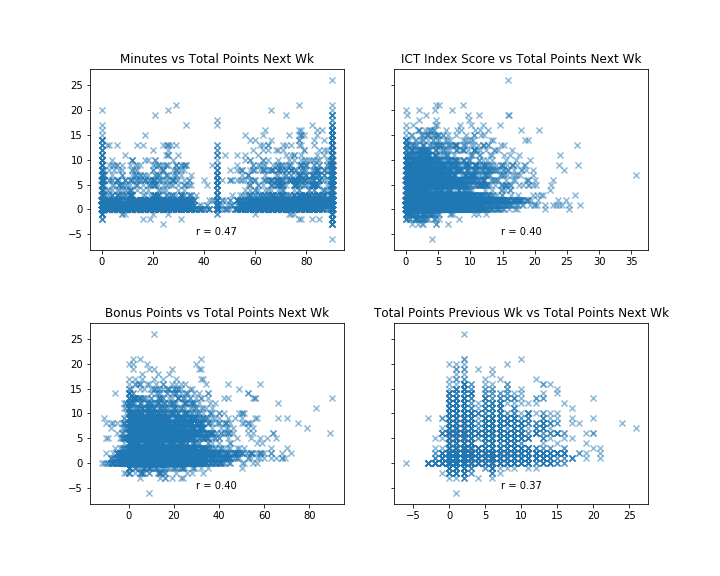
Although nothing here is overly eye-catching, it's still interesting to see how different variables relate to points in the following week. The ICT Index, which is the second-most highly coordinated input variable, is a metric designed by Fantasy Premier League to give insight to a player's value and is essentially just an aggregation of three other scores: Influence, Creativity, Threat.
Model Building
Summary statistics are cool and all I guess, but real fun lies in predicting stuff. The details of the model fitting process can be found in the Github repository, but I found the best model (so far) to be a simple Multiple Linear Regression using the full set of variables. Linear Regression just finds some coefficient value for every input variable, so we can think of the coefficient values as measures of "importance." This model beats the simple baselines I put out — namely predicting last week's points as next week's points, as well as just predicting the average points across all players as the point prediction for every individual player.
Now that it's been proven to capture at least some insight, let's take a look at the coefficients (aka "importances"):
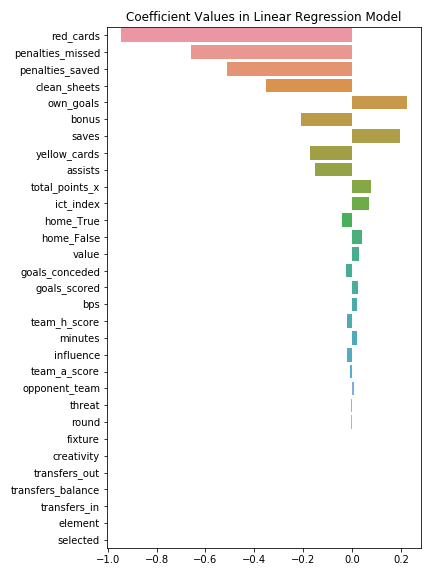
A lot of this is pretty intuitive. For example, red cards have a large negative coefficient value and are the most influential variable in predicting next week's points. If a player gets a red card in the prior week, he'll obviously score zero points the next week due to the inablity to play. Similarly, missing or having penalties saved in the prior week negatively impacts points in the following week — this could be due to a player being benched after having whiffed a PK or perhaps the player's confidence is just a lot lower after a game where he missed a penalty or two. Interestingly, total points in the previous week are not really influential in the prediction of points in the following week.
Not to get too deep, but this might actually say something about human psychology as well. It would seem as if bad events (missing penalties and own goals) have much more of an impact on future performance than positive events (such as goals scored and assists). As a player, and especially a player in arguably the best league on the planet, confidence is an extremely fragile thing. It's not unfathomable to think how a bad game could have a lasting impact to the next week (or even further).
Predicting in the 2020-2021 Season
Given my overly simplified model, let's start applying this freshly trained thing to this year's data. I'll use the first week of the 2020-21 season to predict this past week's points. The input for this model is the data from the first game week of this EPL season, and I'm attempting to predict the points for Week 2 (which already happened but the model doesn't know that).
First off, on average, my model is off by an absolute error of about 1.4 points while a simple baseline of predicting points from Week 1 as a player's points for Week 2, on average, misses the mark by an absolute error of roughly 1.7 points. Although not an astounding difference, it's still nice to know that the model has "learned" something from the data.
Take a look at my predictions compared to the actual points scored:
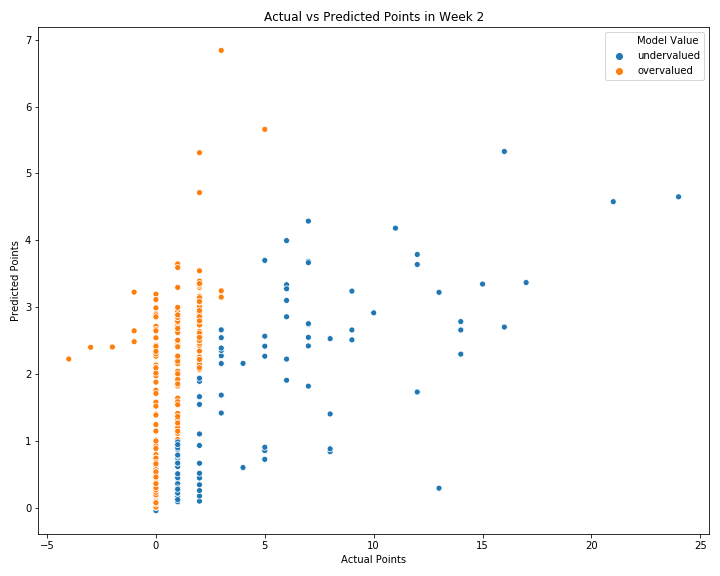
We can see that the model is generally predicting in the right direction, but is lacking some nuance and not capturing all the fluctuations. Honestly, this could turn out to be an impossible task because there are so many factors that we can't account for and the game of soccer is largely a matter of chance and luck. However, I'm going to press forward in an effort to unlock the mystery that is the Fantasy Premier League.
In Conclusion
Google definitely won't be knocking at my door anytime soon with this approach, but nevertheless I feel like I'm walking away with at least a bit more intuition for what's going on.
In the future, I plan on adding in variables like opponent difficulty and recent performances and potentially predicting things like monthly total points instead of a single week at a time since FPL doesn't allow unlimited transfers. Maybe I'll also ramp up the sophistication and borrow concepts from Game Theory, Optimization and Reinforcement Learning to find optimal playing strategies. I could also just get bored or receive a ton of blowback from this and just drop my FPL dreams altogether, so who knows really.
Thanks for following along — see ya next time.


